Weak semantic context helps phonetic learning in a model of infant language acquisition¶
Edinburgh Research Explorer
- Stella Frank :
- sfrank@inf.ed.ac.uk
- ILCC, School of Informatics
- University of Edinburgh
- Edinburgh, EH8 9AB, UK
- Naomi H. Feldman :
- nhf@umd.edu
- Department of Linguistics
- University of Maryland
- College Park, MD, 20742, USA
- Sharon Goldwater :
- sgwater@inf.ed.ac.uk
- ILCC, School of Informatics
- University of Edinburgh
- Edinburgh, EH8 9AB, UK
Abstract¶
Learning phonetic categories is one of the first steps to learning a language, yet is hard to do using only distributional phonetic information. Semantics could potentially be useful, since words with different meanings have distinct phonetics, but it is unclear how many word meanings are known to infants learning phonetic categories. We show that attending to a weaker source of semantics, in the form of a distribution over topics in the current context, can lead to improvements in phonetic category learning. In our model, an extension of a previous model of joint word-form and phonetic category inference, the probability of word-forms is topic-dependent, enabling the model to find significantly better phonetic vowel categories and word-forms than a model with no semantic knowledge.
注釈
音素カテゴリの学習は言語学習の最初のステップであるが、音素の分布的情報のみを使用してこれを行うのは困難である。 異なる意味を持つ単語は異なる音素を持つという意味論は潜在的に効果的であるが音素カテゴリを学習している乳児がどの程度の単語の意味を知っているかは不明確である。 我々は現在の文脈における話題にまたがる分布の形状における弱いセマンティックのソースに付随することは音素カテゴリの学習の向上を導くことを示す. 我々のモデルでは、先行モデルにワードフォームと音素のカテゴリの影響、ワードフォームの確率が話題に依存することを加え拡張した。 また、このモデルはセマンティックの知識を持たないモデルと比べて母音音素カテゴリとワードフォームを有意に優れて学習することを発見した。
1 Introduction¶
Infants begin learning the phonetic categories of their native language in their first year (Kuhl et al., 1992; Polka and Werker, 1994; Werker and Tees, 1984). In theory, semantic information could offer a valuable cue for phoneme induction [1] by helping infants distinguish between minimal pairs, as linguists do (Trubetzkoy, 1939). However, due to a widespread assumption that infants do not know the meanings of many words at the age when they are learning phonetic categories (see Swingley, 2009 for a review), most recent models of early phonetic category acquisition have explored the phonetic learning problem in the absence of semantic information (de Boer and Kuhl, 2003; Dillon et al., 2013; Feldman et al., 2013a; McMurray et al., 2009; Vallabha et al., 2007).
注釈
乳児は初年度に母語の音素カテゴリーの学習を始める (Kuhl et al., 1992; Polka and Werker, 1994; Werker and Tees, 1984). 理論上では, 意味論的情報は乳児のミニマル・ペアを区別を助けることで, 言語学者が行うように, 音素の誘導 [1] のために価値のある手がかりを提供する (Trubetzkoy,1939). しかし, 乳児は, 音素カテゴリを学習している時期では, 多くの単語の意味をしらないという広く知られた仮定(see Swingley, 2009 for a review) のため, 初期音素カテゴリ獲得の最近のモデルは意味論的な情報がない場合の音素の学習問題を調査している. (de Boer and Kuhl, 2003; Dillon et al., 2013; Feldman et al., 2013a; McMurray et al., 2009; Vallabha et al., 2007)
Models without any semantic information are likely to underestimate infants’ ability to learn phonetic categories. Infants learn language in the wild, and quickly attune to the fact that words have (possibly unknown) meanings. The extent of infants’ semantic knowledge is not yet known, but existing evidence shows that six-month-olds can associate some words with their referents (Bergelson and Swingley, 2012; Tincoff and Jusczyk, 1999, 2012), leverage non-acoustic contexts such as objects or articulations to distinguish similar sounds (Teinonen et al., 2008; Yeung and Werker, 2009), and map meaning (in the form of objects or images) to new word-forms in some laboratory settings (Friedrich and Friederici, 2011; Gogate and Bahrick, 2001; Shukla et al., 2011). These findings indicate that young infants are sensitive to co-occurrences between linguistic stimuli and at least some aspects of the world.
注釈
あらゆる意味論的情報を除いたモデルは乳児の音素カテゴリ学習の能力を過小評価しているように見える. 乳児は自然に, 早く, 言葉は(おそらく不明確な)意味を持っているという事実に同調する. 乳児の意味論的知識の範囲はまだ知られていないが, 六ヶ月児はいくつかの単語とその指示対象を関連付けることが可能であることを示す証拠があるし (Bergelson and Swingley, 2012; Tincoff and Jusczyk, 1999, 2012) , 例えば対象や表現など,非音響的コンテキストを利用してよく似た音を区別するし (Teinonen et al., 2008; Yeung and Werker, 2009) , いくつかの実験設定では新しいワードフォームに(オブジェクトや画像の形式で)意味をマッピングすることもできる (Friedrich and Friederici, 2011; Gogate and Bahrick, 2001; Shukla et al., 2011).
In this paper we explore the potential contribution of semantic information to phonetic learning by formalizing a model in which learners attend to the word-level context in which phones appear (as in the lexical-phonetic learning model of Feldman et al., 2013a) and also to the situations in which word-forms are used. The modeled situations consist of combinations of categories of salient activities or objects, similar to the activity contexts explored by Roy et al. (2012), e.g., ‘getting dressed’ or ‘eating breakfast’. We assume that child learners are able to infer a representation of the situational context from their non-linguistic environment. However, in our simulations we approximate the environmental information by running a topic model (Blei et al., 2003) over a corpus of childdirected speech to infer a topic distribution for each situation. These topic distributions are then used as input to our model to represent situational contexts.
注釈
本稿では音素が出現する単語レベルの文脈やワードフォームが使用される文脈を付与した 学習者モデル(Feldman et al., 2013a の 語彙-音素 学習モデルにあるようなモデル)を定式化することで音素学習に対する意味論的情報の潜在的な寄与を調査した. モデル化の状態は, 例えば, 「ドレスを着る」とか「朝食を食べる」のように, 顕著な活動や対象のカテゴリの組み合わせからなり, Roy et al., (2012) の調査したアクティビティコンテキストに似たものである. 我々は乳児がその日言語的環境から状況的文脈の表現を推測することができると仮定した. しかし, 我々のシミュレーションでは, 対児童発話のコーパス上のそれぞれの状況で Topic 分布 を推定するトピックモデル (Blei et al., 2003) を実行した. これらの トピック分布は状況のコンテキストを再提示する我々のモデルへのインプットとして使用した.
The situational information in our model is similar to that assumed by theories of cross-situational word learning (Frank et al., 2009; Smith and Yu, 2008; Yu and Smith, 2007), but our model does not require learners to map individual words to their referents. Even in the absence of word-meaning mappings, situational information is potentially useful because similar-sounding words uttered in similar situations are more likely to be tokens of the same lexeme (containing the same phones) than similarsounding words uttered in different situations.
注釈
我々のモデルにおける状況的情報とは,クロス状況的単語学習の理論 (Frank et al., 2009; Smith and Yu, 2008; Yu and Smith, 2007) が想定しているものに似ているが, 我々のモデルでは独立した単語とその指し示すものとのマッピングを学習者に要求しない. よく似た状況において発話させたよく似た音は (同じ音素を含む) 同じ語彙のトークン である可能性が,他の様々な状況での似たような音よりも高いため, 単語と意味のマッピングが欠落している時にさえ, 状況的な情報は有効である可能性がある.
In simulations of vowel learning, inspired by Vallabha et al. (2007) and Feldman et al. (2013a), we show a clear improvement over previous models in both phonetic and lexical (word-form) categorization when situational context is used as an additional source of information. This improvement is especially noticeable when the word-level context is providing less information, arguably the more realistic setting. These results demonstrate that relying on situational co-occurrence can improve phonetic learning, even if learners do not yet know the meanings of individual words.
注釈
母音学習のシミュレートでは Vallabha et al. (2007) や Feldman et al. (2013a) にインスパイアされ, 我々は状況の文脈は追加された情報源として使用される場合に, 音素と語彙(ワードフォーム) 両方のカテゴリゼーションにおける先行モデル以上に明らかな向上を示す. 単語レベルの文脈の情報が少なく, 間違いなく, より現実的な設定を提供したときにこの改良は特に目立つ. これらの結果は状況の共起に頼ることで, 学習者がまだ個々の単語の意味を知らなくても、音声的な学習を向上させることが可能であると示す.
注釈
| [1] | (1, 2) The models in this paper do not distinguish between phonetic and phonemic categories, since they do not capture phonological processes (and there are also none present in our synthetic data). We thus use the terms interchangeably. 本誌におけるモデルは,音素カテゴリと音素は音韻プロセスを取得しないため (そして,我々の人工データで提示もされないため), 音素カテゴリと音素を区別しない. |
2 Background and overview of models¶
Infants attend to distributional characteristics of their input (maye et al., 2002, 2008), leading to the hypothesis that phonetic categories could be acquired on the basis of bottom-up distributional learning alone (de Boer and Kuhl, 2003; Vallabha et al., 2007; McMurray et al., 2009). However, this would require sound categories to be well separated, which often is not the case—for example, see :num:`Figure #fig1`, which shows the English vowel space that is the focus of this paper.
注釈
乳児はそれらの入力の分布的な特徴に注目をする(maye et al., 2002, 2008). これは, 音素カテゴリはボトムアップに分布の学習のみに基づいて獲得できるという仮説につながった(de Boer and Kuhl, 2003; Vallabha et al., 2007; McMurray et al., 2009).
これは音響カテゴリが分離されていることを要求しているが, しばしば,そうではない例がある. 例えば :num:`図 #fig1` を見て欲しい. ここには本稿で注目する英語母音空間を示す.

英語母音空間(Hillenbrand ら(1995) の6.2節より引用).第一,第二フォルマントを図示する.
Recent work has investigated whether infants could overcome such distributional ambiguity by incorporating top-down information, in particular, the fact that phones appear within words. At six months, infants begin to recognize word-forms such as their name and other frequently occurring words (Mandel et al., 1995; Jusczyk and Hohne, 1997), without necessarily linking a meaning to these forms. This ‘protolexicon’ can help differentiate phonetic categories by adding word contexts in which certain sound categories appear (Swingley, 2009; Feldman et al., 2013b). To explore this idea further, Feldman et al. (2013a) implemented the Lexical-Distributional (LD) model, which jointly learns a set of phonetic vowel categories and a set of word-forms containing those categories. Simulations showed that the use of lexical context greatly improved phonetic learning.
注釈
最近の研究では乳児がこのような分布の曖昧さをトップダウンな情報,とくに音素は単語の中に現れるという情報,を組み込むことで克服することができるのか否かが研究されてきた. 乳児は六ヶ月で, 彼らの名前やその他の頻出する語のようなワードフォームをこれらのフォームの意味の関連は必要なとも, 認識し始める(Mandel et al., 1995: Jusczyk and Hohne, 1997). この ‘源語彙’ はある音響カテゴリが現れる単語のコンテキストを追加することで,音素カテゴリの分離を手助けする(Swingley, 2009; Feldman et al., 2013b). この考えを更に深めるため, Feldman et al. (2013a) では “語彙-分布モデル ( LD モデル )” を実装した. このモデルは母音音素カテゴリのセットとこれらのカテゴリを含む ワードフォームのセットを共同学習するものである. シミュレーションでは、語彙的文脈の使用が大幅に音素学習を改善したことを示した.
Our own Topic-Lexical-Distributional (TLD) model extends the LD model to include an additional type of context: the situations in which words appear. To motivate this extension and clarify the differences between the models, we now provide a high-level overview of both models; details are given in Sections 3 and 4.
注釈
我々は LDモデル を拡張し, 新たにコンテキストの種類を一つ追加した “話題-語彙-分布 モデル (TLD)” を作成した. ここで追加したものは 単語が出現する状況である. この拡張の動機とモデル間の違いを明確にするためにここでは,両方のモデルの大まかな概要を提示する. なお,モデルの詳細は 3,4章 で述べる.
2.1 Overview of LD model¶
Both the LD and TLD models are computationallevel models of phonetic (specifically, vowel) categorization where phones (vowels) are presented to the model in the context of words. [2] The task is to infer a set of phonetic categories and a set of lexical items on the basis of the data observed for each word token \(x_i\) . In the original LD model, the observations for token \(x_i\) are its frame \(f_i\) , which consists of a list of consonants and slots for vowels, and the list of vowel tokens \(w_i\). (The TLD model includes additional observations, described below.) A single vowel token, \(w_{ij}\) , is a two dimensional vector representing the first two formants (peaks in the frequency spectrum, ordered from lowest to highest). For example, a token of the word kitty would have the frame \(f_i = \text{k\_t\_}\) , containing two consonant phones, /k/ and /t/, with two vowel phone slots in between, and two vowel formant vectors, \(w_{i0} = [464, 2294] \text{ and } w_{i1} = [412, 2760]\). [3]
注釈
LD, TDL 両モデルとも, 単語における音素(母音)の出現位置をモデルに教え, 音素 (特に母音) のカテゴリ分類を行う計算モデルである. [2] ここでの課題は観察されたそれぞれの単語トークン \(x_i\) に基づいて, 音素カテゴリのセットと語彙要素のセットを推測することである. 元々の LD モデルにおいては, トークン \(x_i\) に対する観察対象は そのフレーム \(f_i\) である. これは子音のリストと母音のスロットと, 母音トークン \(w_i\) のリストで構成されている ( TLD モデルでは, 以下に記載する追加の対象も含む ). 一つの母音トークン \(w_{ij}\) は 第一,第二フォルマント(低次から高次に並べた際のスペクトラムの頻度のピーク)で表現される 2次元のベクトルである. 例えば, “Kitty” という語のトークンはフレーム \(f_i = \text{k\_t\_}\) を持ち, 2つの母音スロットをその間に持つ, 2つの子音音素/k/, /t/を持ち, そして2つの母音ベクトル \(w_{i0} = [464, 2294] \text{ and } w_{i1} = [412, 2760]\). [3]
Given the data, the model must assign each vowel token to a vowel category, \(w_{ij} = c\). Both the LD and the TLD models do this using intermediate lexemes, \(\ell\) , which contain vowel category assignments, \(\nu_{\ell j} = c\), as well as a frame \(f_{\ell}\) . If a word token is assigned to a lexeme, \(x_i = \ell\), the vowels within the word are assigned to that lexeme’s vowel categories, \(w_{ij} = \nu_{\ell j} = c\) . [4] The word and lexeme frames must match, \(f_i = f_{\ell}\) .
注釈
データを与えると, モデルはそれぞれの母音トークンを母音カテゴリ \(w_{ij} =c\) に割り当てる. LD, TLD モデルの両方で, 中間の語彙 \(f_{\ell}\) を使用してこれを行う. ここにはフレーム \(f_{\ell}\) と同じく母音カテゴリの割り当て \(\nu_{\ell j} = c\) を含む. 単語トークンがある語彙に割り当てられた場合 \(x_i = \ell\), その語に含まれる母音は語彙の母音カテゴリに割り当てられる, \(w_{ij} = \nu_{\ell j} =c\) [4] . その単語と語彙フレームは一致するはずである, \(f_i = f_{\ell}\) .
Lexical information helps with phonetic categorization because it can disambiguate highly overlapping categories, such as the \(ae\) and \(eh\) categories in :num:`Figure #fig1`. A purely distributional learner who observes a cluster of data points in the \(ae-eh\) region is likely to assume all these points belong to a single category because the distributions of the categories are so similar. However, a learner who attends to lexical context will notice a difference: contexts that only occur with \(ae\) will be observed in one part of the \(ae-eh\) region, while contexts that only occur with \(eh\) will be observed in a different (though partially overlapping) space. The learner then has evidence of two different categories occurring in different sets of lexemes.
注釈
語彙情報は例えば, :num:`図 #fig1` にある \(ae\) と \(eh\) のような カテゴリの重度な重複の曖昧さをなくすため,音素のカテゴリゼーションを手助けする. \(ae-eh\) 領域のデータポイントの中心を観察する純粋な分布学習者はカテゴリの分布が非常に似ているため, これらすべてのポイントは単一のカテゴリであると割り当てるだろう. しかし, 語彙コンテキストに注目する学習者は \(ae\) は \(ae-eh\) 領域の一部で 観察されるというコンテキストと, 一方 \(eh\) は異なる(ただし部分的には重複する) 空間でのみ観察されると いうコンテキストがあるため, 違いに気がつくことができる. そのため, 学習者は2つの異なるカテゴリが異なる語彙のセットにおいて生じるという証拠を持っている.
Simulations with the LD model show that using lexical information to constrain phonetic learning can greatly improve categorization accuracy (Feldman et al., 2013a), but it can also introduce errors. When two word tokens contain the same consonant frame but different vowels (i.e., minimal pairs), the model is more likely to categorize those two vowels together. Thus, the model has trouble distinguishing minimal pairs. Although young children also have trouble with minimal pairs (Stager and Werker, 1997; Thiessen, 2007), the LD model may overestimate the degree of the problem. We hypothesize that if a learner is able to associate words with the contexts of their use (as children likely are), this could provide a weak source of information for disambiguating minimal pairs even without knowing their exact meanings. That is, if the learner hears \(k V_1 t\) and \(k V_2 t\) in different situational contexts, they are likely to be different lexical items (and \(V_1\) and \(V_2\) different phones), despite the lexical similarity between them.
注釈
LDモデルのシミュレーションは音素学習を制約する語彙情報を用いることで大幅に分類精度を向上させることができることを示しており(Feldman et al., 2013a), それはまた、エラーを導くことにもなりうる. 異なる母音で同じ子音のフレームを含む二語のトークン(すなわち、ミニマルペア)では, モデルは、これら二つの母音を同じものとして分類する可能性が高い. したがって, このモデルではミニマルペアの区別は難しい. 一方, 乳児もまたミニマルペアに関しては問題があり (Stager and Werker, 1997; Thiessen, 2007), LD モデルは問題の程度を過大評価できる. 我々は学習者が(子供がそうであるように)その使用の文脈で言葉を関連付けすることができる場合には, その正確な意味を知らなくても ミニマルペアの曖昧性に対する弱い情報源を提供することができると仮定した. これは,学習者が異なる状況のコンテキストで \(k V_1 t\) と \(k V_2 t\) という語を聞いた場合, それらの間の語彙的類似性にもかかわらず, それらは異なる語彙項目である可能性が高く (そして \(V_1\) と \(V_2\) は異なる音素である) と判断できる.
脚注
| [2] | (1, 2) For a related model that also tackles the word segmentation problem, see Elsner et al. (2013). In a model of phonological learning, Fourtassi and Dupoux (submitted) show that semantic context information similar to that used here remains useful despite segmentation errors. 単語分割問題に取り組む関連モデルについては, Elsner et al. (2013) を参照. 音素学習モデルでは Fourtassiと Dupoux (submitted) が本稿で使用したのと同様のセマンティックコンテキスト情報を利用してセグメンテーションエラーに対しても有効なことを示しています. |
| [3] | (1, 2) In simulations we also experiment with frames in which consonants are not represented perfectly. シミュレーションでは,子音が完全に表現されていないフレームを使用する実験も行った. |
| [4] | (1, 2) The notation is overloaded: wij refers both to the vowel formants and the vowel category assignments, and xi refers to both the token identity and its assignment to a lexeme. 表記は多重定義されている: \(w_{ij}\) は母音フォルマントと母音カテゴリの割り当てを言及しており, \(x_i\) はトークンID と その語彙に対する割り当てを言及している. |
2.2 Overview of TLD model¶
To demonstrate the benefit of situational information, we develop the Topic-Lexical-Distributional (TLD) model, which extends the LD model by assuming that words appear in situations analogous to documents in a topic model. Each situation \(h\) is associated with a mixture of topics \(theta_h\) , which is assumed to be observed. Thus, for the \(i\) th token in situation \(h\), denoted \(x_{hi}\) , the observed data will be its frame \(f_{hi}\) , vowels \(w_{hi}\) , and topic vector \(\theta_h\) .
注釈
状況の情報を利用する利点を実証するために, 我々は 話題-単語-分布モデルを開発した. これはその語が 類似した話題の文章で生じるという Topic モデルを仮定することにより LD モデルを拡張したものである. それぞれの状況 \(h\) は観察された話題 \(\theta_h\) の混合と関連している. したがって, ある状況 \(h\) における \(i\) 番目のトークン, 以後 \(x_{hi}\) と表記, のために 観察されたデータは そのフレーム \(f_{hi}\), 母音 \(w_{hi}\), そして Topic ベクトル \(\theta_h\) となる.
From an acquisition perspective, the observed topic distribution represents the child’s knowledge of the context of the interaction: she can distinguish bathtime from dinnertime, and is able to recognize that some topics appear in certain contexts (e.g. animals on walks, vegetables at dinnertime) and not in others (few vegetables appear at bathtime). We assume that the child would learn these topics from observing the world around her and the co-occurrences of entities and activities in the world. Within any given situation, there might be a mixture of different (actual or possible) topics that are salient to the child. We assume further that as the child learns the language, she will begin to associate specific words with each topic as well.
注釈
獲得の視点からは, 観察された話題分布はインタラクションのコンテキストに対する子供の知識を表現している. 彼女は夕食時とバスタイムを区別することができるし, いくつかのトピックは特定の状況でのみ出現するし, また他の物は出ないことを認識することができる (例えば,散歩時には動物の話題が,夕食時には野菜の話題が出現するが, お風呂では野菜の話題にはなりにくい). 我々は子供は周囲の世界を観察することでこれらの話題を学習することができ, 周囲の世界において同時に活性化する共起物を学習できると仮定した. 与えられたあらゆる情報において, 子供に顕著な異なる話題 (実際的にしろ,可能な形にしろ ) の混同があるかもしれない. 我々は更に, 乳児が単語を学習している際に, 同様に各話題に特定の単語を関連付けることも開始すると仮定した.
Thus, in the TLD model, the words used in a situation are topic-dependent, implying meaning, but without pinpointing specific referents. Although the model observes the distribution of topics in each situation (corresponding to the child observing her non-linguistic environment), it must learn to associate each (phonetically and lexically ambiguous) word token with a particular topic from that distribution. The occurrence of similar-sounding words in different situations with mostly non-overlapping topics will provide evidence that those words belong to different topics and that they are therefore different lexemes. Conversely, potential minimal pairs that occur in situations with similar topic distributions are more likely to belong to the same topic and thus the same lexeme.
注釈
したがって TLD モデルでは, 単語は 話題に依存する状況において使用され, 特定の対処を決めることなく,意味を暗示する. モデルは,それぞれの状況にある話題の分布を観察し(これは子供が非言語的な環境を観察することに相当します), その分布から特定のトピックに関連するそれぞれの(音声学と辞書的に曖昧な)単語トークンを学ぶ必要がある. 大部分が重複しない話題について,様々な状況での発音の似た単語の出現は,これらの単語が別の話題に属しており,したがって異なる語彙であることを示す証拠になる. 逆に、似たような話題の分布をもつ状況での潜在的なミニマルペアは、同じトピックに属している可能性が高いので、同じ語彙になる.
Although we assume that children infer topic distributions from the non-linguistic environment, we will use transcripts from CHILDES to create the word/phone learning input for our model. These transcripts are not annotated with environmental context, but Roy et al. (2012) found that topics learned from similar transcript data using a topic model were strongly correlated with immediate activities and contexts. We therefore obtain the topic distributions used as input to the TLD model by training an LDA topic model (Blei et al., 2003) on a superset of the child-directed transcript data we use for lexical-phonetic learning, dividing the transcripts into small sections (the ‘documents’ in LDA) that serve as our distinct situations \(h\) . As noted above, the learned document-topic distributions \(\theta\) are treated as observed variables in the TLD model to represent the situational context. The topic-word distributions learned by LDA are discarded, since these are based on the (correct and unambiguous) words in the transcript, whereas the TLD model is presented with phonetically ambiguous versions of these word tokens and must learn to disambiguate them and associate them with topics.
注釈
我々は子供が話題の分布を非言語的な環境から推測していると仮定しているため, CHILDES [5] の転機を我々のモデルの 語/音素 学習用のインプット作成に使用した. これらの転機は環境コンテキストがアノテーションされていないが, Roy et al. (2012) は Topic モデルを使用して, 似たような転機データから, 学習された話題は即時行動や文脈と強い相関を持っていることを発見している. そのため, 我々が転記を明確な状況 \(h\) として機能する小さなセクションに分割し,語彙-音素を学習するのために使用する子供に対する書き起こしデータのスーパーセットを LDA Topic モデル [6] で訓練することで, TLD モデルへの入力として使用する話題分布を入手した. 上述した通り,状況的文脈を表現するためにTLDモデルで観測変数として, 訓練された文章-話題分布 \(theta\) は訓練された. LDAによって学習トピックワード分布は, TLDモデルが単語トークンの音声学的に曖昧なバージョンが提示され, それらを明確にし,話題に関連付けることを学習する必要があるのに対し, 転記情報中の(正しく,明確な)単語に基づいているため, LDAによって学習トピックワード分布は破棄された.
訳者注
| [5] | CHILDES(チャイルズ、CHild Language Data Exchange System ) : 第一言語獲得研究用のデータベース |
| [6] | LDA Topic Model : 最近の Topic Model の代表的な実装方法
|
3 Lexical-Distributional Model¶
In this section we describe more formally the generative process for the LD model (Feldman et al., 2013a), a joint Bayesian model over phonetic categories and a lexicon, before describing the TLD extension in the following section.
注釈
本章では, LD モデル (Feldman et al., 2013a) における生成プロセス, 音素カテゴリと語彙に対するベイジアンモデルの接続部分をより本質的に記述する. その後, TLD 拡張をこの章の続きに記述する.
The set of phonetic categories and the lexicon are both modeled using non-parametric Dirichlet Process priors, which return a potentially infinite number of categories or lexemes. A DP is parametrized as \(DP (\alpha, H)\), where \(\alpha\) is a real-valued hyperparameter and \(H\) is a base distribution. \(H\) may be continuous, as when it generates phonetic categories in formant space, or discrete, as when it generates lexemes as a list of phonetic categories.
注釈
音素カテゴリのセットと語彙の両方はノンパラメトリックなディリクレ過程 (DP) 事前分布でモデリングされている. これは, 潜在的には無限個のカテゴリや語彙を返す. 一つの DP は パラメタ \(DP(\alpha, H)\) によって規定される. \(\alpha\) は実数値であり, ハイパラメータ \(H\) はベースとなる分布である. \(H\) はそれが音素カテゴリのリストとして語彙を生成する場合や, フォルマント空間の音素カテゴリを生成する場合などには, 連続値をとる.
A draw from a \(DP, G ∼ DP (\alpha, H)\) , returns a distribution over a set of draws from \(H\), i.e., a discrete distribution over a set of categories or lexemes generated by \(H\). In the mixture model setting, the category assignments are then generated from \(G\), with the datapoints themselves generated by the corresponding components from \(H\). If \(H\) is infinite, the support of the \(DP\) is likewise infinite. During inference, we marginalize over \(G\).
注釈
\(DP, G ~ (\alpha, H)\) からの描画は \(H\) からの描画のセット上に 例えば, \(H\) によって生成されたカテゴリまたは語彙素のセットに対する離散分布などの分布を返す. ついで,混合モデル設定では, \(H\) 由来の対応するコンポーネントによって生成されたデータポイントを持つ, カテゴリの割り当てを \(G\) から生成する \(H\) が無限の場合, \(DP\) のサポートもまた無限である. 推論の間, \(G\) を最小化した.
3.1 Phonetic Categories: IGMM¶
Following previous models of vowel learning (de Boer and Kuhl, 2003; Vallabha et al., 2007; McMurray et al., 2009; Dillon et al., 2013) we assume that vowel tokens are drawn from a Gaussian mixture model. The Infinite Gaussian Mixture Model (IGMM) (Rasmussen, 2000) includes a DP prior, as described above, in which the base distribution \(H_C\) generates multivariate Gaussians drawn from a Normal Inverse-Wishart prior. [7] Each observation, a formant vector \(w_{ij}\) , is drawn from the Gaussian corresponding to its category assignment \(c_{ij}\) :
注釈
母音学習の先行研究 (de Boer and Kuhl, 2003; Vallabha et al., 2007; McMurray et al., 2009; Dillon et al., 2013) にしたがって, 我々は, 母音トークンは ガウス混合分布モデルにしたがって起きるものであると過程した. Infinite Gaussian Mixture Model (IGMM) (Rasmussen, 2000) は上述の DP を含み, Normal Inverse-Wishart事前分布から描かれる多変量カウス分布を 基本分布 \(H_C\) から生成する. 各観測では, フォルマントベクトル \(w_{ij}\) はカテゴリ割り当て \(c_{ij}\) に対応するガウシアンより, 描かれる.
The above model generates a category assignment \(c_{ij}\) for each vowel token \(w_{ij}\) . This is the baseline IGMM model, which clusters vowel tokens using bottom-up distributional information only; the LD model adds top-down information by assigning categories in the lexicon, rather than on the token level.
注釈
上記のモデルはそれぞれの母音トークン \(w_{ij}\) に対するカテゴリ割り当て \(c_{ij}\) を生成する. これが, ボトムアップな分布の情報のみを使用して母音トークンをクラスタ化する IGMM モデルである. LD モデルはトークンレベルで語彙内のカテゴリを割り当てるのではなく、トップダウンの情報が追加される.
脚注
| [7] | This compound distribution is equivalent to \(\Sigma_c ∼ IW(\Sigma_0 , \nu_0 ), \mu_c | \Sigma_c ∼ N (\mu_0 , \frac{\sigma_c}{\nu_0})\) |
3.2 Lexicon¶
In the LD model, vowel phones appear within words drawn from the lexicon. Each such lexeme is represented as a frame plus a list of vowel categories \(\nu_{\ell}\) . Lexeme assignments for each token are drawn from a DP with a lexicon-generating base distribution \(H_L\) . The category for each vowel token in the word is determined by the lexeme; the formant values are drawn from the corresponding Gaussian as in the IGMM:
注釈
LDモデルでは、母音音素は、語彙から引き出された単語中に現れる. それぞれの語彙素性はフレームと母音カテゴリ \(\nu_{\ell}\) のリストとして表現される. 語彙素性はそれぞれのトークンに割り当てられ, 語彙生成基本分布 \(H_L\) を持つ DP から描かれる. 単語に含まれるそれぞれの母音トークンのカテゴリは語彙素性ごとに探索される. IGMMのように, フォルマントの値は対応するガウシアンから描かれる.
\(H_L\) generates lexemes by first drawing the number of phones from a geometric distribution and the number of consonant phones from a binomial distribution. The consonants are then generated from a DP with a uniform base distribution (but note they are fixed at inference time, i.e., are observed categorically), while the vowel phones \(\nu_{\ell}\) are generated by the IGMM DP above, \(\nu_{\ell j} ∼ GC\) .
注釈
\(H_L\) は幾何分布から最初に描かれる音素の数と二峰性の分布由来の子音音素の数とによって, 語彙素性を生成する. 上記の IGMM DP \(\nu_{\ell j} ∼ GC\) から 母音音素 \(\nu_{\ell}\) が生成される一方, 子音はその後, 均一的な基本分布を持つ DP から生成される (しかし, これらは推論時,例えば,カテゴリ的に観察されているときなど,には固定されることに注意).
Note that two draws from \(H_L\) may result in identical lexemes; these are nonetheless considered to be separate (homophone) lexemes.
注釈
\(H_L\) からの2つの描写は独立した語彙素性における結果であることに注目. これらは, それにもかかわらず、別々の(同音)語彙素であると考えられる.
4 Topic-Lexical-Distributional Model¶
The TLD model retains the IGMM vowel phone component, but extends the lexicon of the LD model by adding topic-specific lexicons, which capture the notion that lexeme probabilities are topicdependent. Specifically, the TLD model replaces the Dirichlet Process lexicon with a Hierarchical Dirichlet Process (HDP; Teh (2006)). In the HDP lexicon, a top-level global lexicon is generated as in the LD model. Topic-specific lexicons are then drawn from the global lexicon, containing a subset of the global lexicon (but since the size of the global lexicon is unbounded, so are the topic-specific lexicons). These topic-specific lexicons are used to generate the tokens in a similar manner to the LD model. There are a fixed number of lower level topic-lexicons; these are matched to the number of topics in the LDA model used to infer the topic distributions (see Section 6.4).
注釈
TLD モデル は IGMM の母音コンポーネントを保ってはいるが, 話題に限定的な語彙によって LD モデルの語彙を拡張した. 語彙素性の確率は話題に由来しているという考えをとったものである. 特に, TLD モデルはディレクレ過程の語彙を,階層的ディレクレ過程に置き換えたものである(HDP; Teh (2006)). HDP語彙では, LD モデルの場合のように、トップレベルでグローバルな語彙を生成する。 その後、話題特異な語彙をグローバルな語彙から取り出だす. (しかし、グローバルな語彙のサイズが限られていないので、これは、話題に限定的な語彙になる) これらの話題に限定的な語彙は LD モデルと似た方法でトークンを生成するために使用される. 低レベルの話題の語彙は固定値がある. これらは話題分布を推論するために使用される LDA モデルの中でトピックの数に一致する(6.4章参照)。
More formally, the global lexicon is generated as a top-level \(DP: G_L ∼ DP (\alpha_{\ell} , H_L )\) (see Section 3.2; remember \(H_L\) includes draws from the IGMM over vowel categories). \(G_L\) is in turn used as the base distribution in the topic-level DPs, \(G_k ∼ DP (\alpha_k , G_L )\). In the Chinese Restaurant Franchise metaphor often used to describe HDPs, \(G_L\) is a global menu of dishes (lexemes). The topicspecific lexicons are restaurants, each with its own distribution over dishes; this distribution is defined by seating customers (word tokens) at tables, each of which serves a single dish from the menu: all tokens \(x\) at the same table \(t\) are assigned to the same lexeme \(t\) . Inference (Section 5) is defined in terms of tables rather than lexemes; if multiple tables draw the same dish from \(G_L\) , tokens at these tables share a lexeme.
注釈
より正式に言えば,グローバルな語彙はトップレベル \(DP: G_L ∼ DP (\alpha_{\ell} , H_L )`として作成される (3.2参照: :math:`H_L\) はIGMMから母音カテゴリ上に描かれることに注意). \(G_L\) は話題レベルの DPs \(G_k ∼ DP (\alpha_k , G_L )\)-において基本分布として使用される. HDPs を記述するためにフランチャイズの中華料理屋の比喩がよく使われる. \(G_L\) は皿(語彙素性)のグローバルな一覧である. 話題に限定された語彙はレストランであり,それぞれの皿に対する分布を持っている. この分布は座席に座る客(単語トークン)によってテーブルで定義され, これらはそれぞれメニューから一つの皿を給仕する. 同じテーブル \(t\) のすべてのトークン \(x\) は同じ語彙素性 \(t\) に割り当てられる. 推論(5章)は語彙素性ではなくテーブルの点から定義される. 多数のテーブルが同じ皿を \(G_L\) から引く場合、これらのテーブルのトークンは同じ語彙素性を共有します.
In the TLD model, tokens appear within situations, each of which has a distribution over topics \(\theta_h\) . Each token \(x_{hi}\) has a co-indexed topic assignment variable, \(z_{hi}\) , drawn from \(\theta_h\) , designating the topic-lexicon from which the table for \(x_{hi}\) is to be drawn. The formant values for \(w_{hij}\) are drawn in the same way as in the LD model, given the lexeme assignment at \(x_{hi}\) . This results in the following model, shown in :num:`Figure #fig2`:
注釈
TLD モデルでは,トークンは状況のなかに出現し,これらの状況は話題に対する分布 \(\theta_h\) を持っている. それぞれのトークン \(x_{hi}\) は \(\theta_h\) から描かれる, 共通するインデックスが付与されたトピックの割り当て変数 \(z_{hi}\) を持っている. \(w_{hij}\) に対するフォルマントの値は LD モデルの場合と同様の方法で描かれ, \(x_{hi}\) に割り当てられた語彙素性を与えられる. モデルに従った結果を :num:`図 #fig2` に示す.
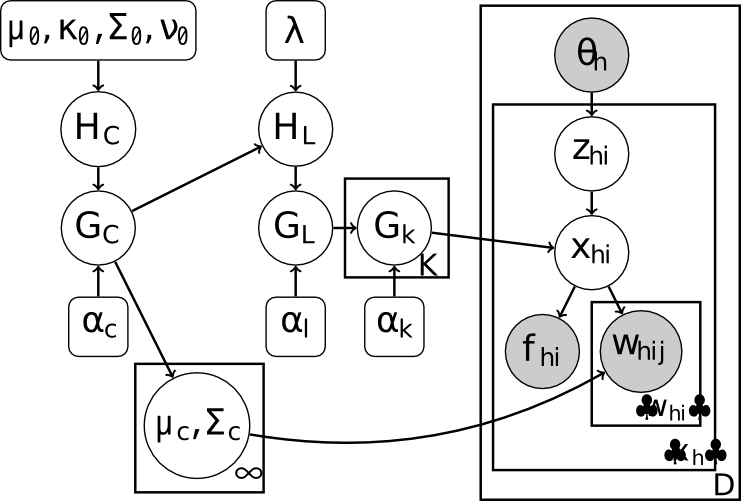
左から右へ TDL モデル, IGMMコンポーネント, LD 語彙コンポーネント, 話題に限定的な語彙, 最後に文章 \(h\) に現れるトークン \(x_{hi}\) と 観察された母音フォルマント \(w_{hij}\) と フレーム \(f_{hi}\)
The lexeme assignment \(x_{hi}\) and the topic assignment \(z_{hi}\) are inferred, the latter using the observed documenttopic distribution \(theta_h\) . Note that \(f_i\) is deterministic given the lexeme assignment. Squared nodes depict hyperparameters. \(\lambda\) is the set of hyperparameters used by \(H_L\) when generating lexical items (see Section 3.2).
注釈
語彙素性割り当て \(x_{hi}\) と, 話題割り当て \(z_{hi}\) は推定され, 後者は観察された文章分布 \(theta_h\) に使用される. \(f_i\) は決定論的な与えられた語彙素性割り当てであることに注意. ノードの2乗はハイパーパラメータを描く. \(\lambda\) は語彙アイテムを生成する際に \(H_L\) によって使用されるハイパーパラメータのセットである( 3.2 章参照 ).
5 Inference: Gibbs Sampling¶
We use Gibbs sampling to infer three sets of variables in the TLD model: assignments to vowel categories in the lexemes, assignments of tokens to topics, and assignments of tokens to tables (from which the assignment to lexemes can be read off).
注釈
我々は Gibbs sampling を TLD モデルの 変数の木構造セットを推定するために使用した. 語彙素性に含まれる母音カテゴリへの割り当て, トークンの話題に対する割り当て, そして, トークンのテーブルに対する割り当てである (そこから語彙素への割り当てが読み取ることができる).
5.1 Sampling lexeme vowel categories¶
Each vowel in the lexicon must be assigned to a category in the IGMM. The posterior probability of a category assignment is composed of the DP prior over categories and the likelihood of the observed vowels belonging to that category. We use \(w_{\ell j}\) to denote the set of vowel formants at position \(j\) in words that have been assigned to lexeme . Then,
注釈
語彙に含まれるそれぞれの母音はIGMMにおいて一つのカテゴリへ割り当てられることになる. カテゴリの割り当ての事後分布はカテゴリに対する DP 事前分布 と そのカテゴリに属している観察された母音の尤度から構成されている. \(w_{\ell j}\) を語彙素性に割り当てられた単語のポジション \(j\) にある母音フォルマントのセットを示すために使用した. すなわち,
The first (DP prior) factor is defined as:
注釈
第一 ( DP 事前分布 ) 因子は以下のように定義した:
where \(n_c\) is the number of other vowels in the lexicon, \(\mu^{\backslash \ell j}\) , assigned to category \(c\). Note that there is always positive probability of creating a new category.
注釈
\(n_c\) の部分はカテゴリ \(c\) に割り当てられた語彙 \(\mu^{\backslash \ell}\) に含まれる他の母音数である. 新しいカテゴリの肯定的な可能性が常にあることに注意して欲しい.
The likelihood of the vowels is calculated by marginalizing over all possible means and variances of the Gaussian category parameters, given the NIW prior. For a single point \((\text{if} | w_{\ell j} | = 1)\), this predictive posterior is in the form of a Student-t distribution; for the more general case see Feldman et al. (2013a), Eq. B3.
注釈
母音の尤度は NIW 事前分布に与えられたガウスカテゴリパラメータのありうるすべての平均と分散のを無視することによって計算される. 一つの点 \(\text{if} | w_{\ell j} | =1\) に対して,この予想後部は スチューデントの t 分布の形式の中にある. より一般的な場合に関しては Feldman et al. (2013a), Eq. B3 を参照して欲しい.
5.2 Sampling table & topic assignments¶
We jointly sample \(x\) and \(z\), the variables assigning tokens to tables and topics. Resampling the table assignment includes the possibility of changing to a table with a different lexeme or drawing a new table with a previously seen or novel lexeme. The joint conditional probability of a table and topic assignment, given all other current token assignments, is:
注釈
我々は \(x\) と \(z\), テーブルや話題へ割り当てられるトークンの変数を 共にサンプリングした. テーブルの割り当てをリサンプリングすることは 異なる語彙素性を使用してテーブルに変更したり、 以前に見られたまたは新規語彙を持つ新しいテーブルを描画する可能性を含んでいる. すべての他のトークン割り当てが与えられた,テーブルと話題割り当ての同時条件付き確率は 以下の通り.
The first factor, the prior probability of topic \(k\) in document \(h\), is given by \(\theta_{hk}\) obtained from the LDA. The second factor is the prior probability of assigning word \(x_i\) to table \(t\) with lexeme given topic \(k\). It is given by the HDP, and depends on whether the table \(t\) exists in the HDP topic-lexicon for \(k\) and, likewise, whether any table in the topiclexicon has the lexeme :
注釈
第一要素,ドキュメント \(h`に含まれる話題の事前確率 :math:`k\) ,は LDA から得られた \(\theta_{hk}\) によって与えられる. 第二要素は 単語 \(x_i\) を 話題 \(k\) が与えられた語彙素性を持つテーブル \(t\) へ割り当てる事前確率である. これは HDP より与えられ, \(k`に対する話題語彙 HDP のどこにテーブル :math:`t\) が存在するのかと同様に 語彙素性をもつ話題語彙に含まれるすべてのテーブルがどこにあるのかに依存する.
Here \(n_{kt}\) is the number of other tokens at table \(t\), \(n_k\) are the total number of tokens in topic \(k\), \(m_{\ell}\) is the number of tables across all topics with the lexeme \(\ell\) , and \(m\) is the total number of tables.
注釈
ここで \(n_{kt}\) はテーブル \(t\) の他のトークンの数であり, \(n_k\) は話題 \(k\) に含まれるトークンの総和である. また,\(\ell\) は語彙素性 \(\ell\) を含むすべての話題に渡ったテーブル数であり, \(m\) はテーブルの総和である.
The third factor, the likelihood of the vowel formants \(w_{hi}\) in the categories given by the lexeme \(\mu_{\ell}\) , is of the same form as the likelihood of vowel categories when resampling lexeme vowel assignments. However, here it is calculated over the set of vowels in the token assigned to each vowel category (i.e., the vowels at indices where \(\mu_{\ell t \dot} = c\) ). For a new lexeme, we approximate the likelihood using 100 samples drawn from the prior, each weighted by \(\alpha/100\) (Neal, 2000).
注釈
第三要素は,語彙素性 \(\mu_{\ell}\) によって与えられた カテゴリに含まれる母音フォルマント \(w_{hi}\) の尤度であり, 語彙素性母音割り当てをリサンプリングした際の母音カテゴリの尤度と同じ形状である. しかし,ここで,それは 各母音カテゴリ(例えば,\(\mu_{\ell t \dot} = c\) の部分の索引の母音) に割り当てられたトークンに含まれる母音セットに渡って計算される. 新しい語彙素性のために, それぞれ \(\alpha/100\) によって重み付けられた 事前分布から取られた 100 サンプル を使用した尤度を近似した (Neal, 2000).
5.3 Hyperparameters¶
The three hyperparameters governing the HDP over the lexicon, \(\alpha_{\ell}\) and \(\alpha_{k}\) , and the DP over vowel categories, \(\alpha_c\) , are estimated using a slice sampler. The remaining hyperparameters for the vowel category and lexeme priors are set to the same values used by Feldman et al. (2013a).
注釈
語彙 \(\alpha_{\ell}\) と \(\alpha_{k}\) に対する HDP , そして母音カテゴリに対する DP を決める 3つのハイパラメータ は スライスサンプラー を使用して推定された. 語彙素性と母音カテゴリの事前分布に対するハイパラメータは Feldman et al. (2013a) で 使用された値と同じ値のセットである.
6 Experiments¶
6.1 Corpus¶
We test our model on situated child directed speech, taken from the C1 section of the Brent corpus in CHILDES (Brent and Siskind, 2001; MacWhinney, 2000). This corpus consists of transcripts of speech directed at infants between the ages of 9 and 15 months, captured in a naturalistic setting as parent and child went about their day. This ensures variability of situations.
注釈
我々は対児童音声の上でモデルのテストを行った. これは, Brent が作成したコーパス CHILDS に含まれるセクション C1 にある ( Brent and Siskind, 2001; Macwhinney, 2000). このコーパスは 9-15ヶ月 の間の乳児に対して話しかけられた転記テキストによって構成されていて, 親子の日常について自然なセッティングで収録されたものである. これは状況の変動性を保証する.
Utterances with unintelligible words or quotes are removed. We restrict the corpus to content words by retaining only words tagged as adj, n, part and v (adjectives, nouns, particles, and verbs). This is in line with evidence that infants distinguish content and function words on the basis of acoustic signals (Shi and Werker, 2003). Vowel categorization improves when attending only to more prosodically and phonologically salient tokens (Adriaans and Swingley, 2012), which generally appear within content, not function words. The final corpus consists of 13138 tokens and 1497 word types.
注釈
理解できない単語や引用符をもつ発話は削除した. 我々は, ADJ, N, part, V (形容詞, 名詞, 句, 及び,動詞) としてタグ付けられた単語だけを保持することで, 内容語のみにコーパスを制限した. これは乳児が音響信号に基づいて, 内容語や機能語を区別しているという証拠に基づいたものである(Shi and Werker, 2003). 母音のカテゴリ化はより韻律的, 音韻的に顕著なトークンのみに注目した時に向上し(Adriaans and Swingley, 2012), それらのトークンは一般に機能語ではなく内容語に現れる. 最終的に, 13138 トークン, 1497の単語タイプのデータを使用した.
6.2 Hillenbrand Vowels¶
The transcripts do not include phonetic information, so, following Feldman et al. (2013a), we synthesize the formant values using data from Hillenbrand et al. (1995). This dataset consists of a set of 1669 manually gathered formant values from 139 American English speakers (men, women and children) for 12 vowels. For each vowel category, we construct a Gaussian from the mean and covariance of the datapoints belonging to that category, using the first and second formant values measured at steady state. We also construct a second dataset using only datapoints from adult female speakers.
注釈
転記テキストは音素情報を含んでいない. そのため, Feldman et al. (2013a) にしたがって, Hillenbrand et al. (1995) 由来のデータを使用したフォルマントの値を合成した. このデータセットは 12 種類の母音に対する 139名 のアメリカ人 (成人男女,子供) から手動で収集された 1669 のフォルマントの値のセットを含んである. それぞれの母音カテゴリに対して, 低上部分の第一第二フォルマントの値を使用したカテゴリに属するデータポイントの平均と分散から正規分布を構築した. 我々は, 成人女性話者のみからのデータポイントを使用した第二データセットも構築した.
Each word in the dataset is converted to a phonemic representation using the CMU pronunciation dictionary, which returns a sequence of Arpabet phoneme symbols. If there are multiple possible pronunciations, the first one is used. Each vowel phoneme in the word is then replaced by formant values drawn from the corresponding Hillenbrand Gaussian for that vowel.
注釈
データセットに含まれる各単語はアルファベット音素シンボルが返される, CMUの発話辞書を使用した音素表現に換算された. 仮に, 発話の選択肢が複数個あった場合には, 最初のものを使用した. 続いて, 単語に含まれる各母音音素はその母音用の Hillenbrand 正規分布に対応するフォルマントの値に変換された.
6.3 Merging Consonant Categories¶
The Arpabet encoding used in the phonemic representation includes 24 consonants. We construct datasets both using the full set of consonants — the ‘C24’ dataset — and with less fine-grained consonant categories. Distinguishing all consonant categories assumes perfect learning of consonants prior to vowel categorization and is thus somewhat unrealistic (Polka and Werker, 1994), but provides an upper limit on the information that word-contexts can give.
注釈
音素表現で使用されたアルファベットエンコーディングには 24 個の子音が含まれていた. 我々は子音のフルセットなデータセット, ‘C24’ データセット, と より詳細で少ない子音カテゴリのものの両方のデータセットを使用した. すべての子音のカテゴリを区別することは母音の分類の前に子音の完璧な学習を前提としていており, したがって,やや非現実的である (Polka and Werker, 1994) が, その単語のコンテキストが与えうる情報の上限を提供している.
In the ‘C15’ dataset, the voicing distinction is collapsed, leaving 15 consonant categories. The collapsed categories are B/P, G/K, D/T, CH/JH, V/F, TH/DH, S/Z, SH/ZH, R/L while HH, M, NG, N, W, Y remain separate phonemes. This dataset mirrors the finding in Mani and Plunkett (2010) that 12 month old infants are not sensitive to voicing mispronunciations.
注釈
‘C15’ データセットには, 15 子音のカテゴリを残して, ボイシングの区別が欠損している. 欠損したカテゴリは B/P, G/K, D/T, CH/JH, V/F, TH/DH, S/Z, SH/ZH, R/L であり, 一方 HH, M, NG, N, W, Y は別々の音素のままである. このデータセットは 12 ヶ月児はボイシングの誤りへの教示に敏感ではないという Mani and Plunkett (2010) での所見を反映している.
The ‘C6’ dataset distinguishes between only 6 coarse consonant phonemes, corresponding to stops (B,P,G,K,D,T), affricates (CH,JH), fricatives (V, F, TH, DH, S, Z, SH, ZH, HH), nasals (M, NG, N), liquids (R, L), and semivowels/glides (W, Y). This dataset makes minimal assumptions about the categories that infants could use in this learning setting.
注釈
‘C6’ データセットは閉鎖音(B、P、G、K、D、T), 破擦音(CH、JH), 摩擦音(V、F、TH、DH、S、Z、SH、ZH、HH), 鼻音(M、NG、N), 流音(R、L), 半母音/グライド(W、Y) に対応する6つの大まかな子音音素のみを区別する. このデータセットはこの学習セットで乳児が使用することができるカテゴリについての最小限の仮定を作る.
Decreasing the number of consonants increases the ambiguity in the corpus: bat not only shares a frame (b t) with boat and bite, but also, in the C15 dataset, with put, pad and bad (b/p d/t), and in the C6 dataset, with dog and kite, among many others (STOP STOP). Table 1 shows the percent age of types and tokens that are ambiguous in each dataset, that is, words in frames that match multiple wordtypes. Note that we always evaluate against the gold word identities, even when these are not distinguished in the model’s input. These datasets are intended to evaluate the degree of reliance on consonant information in the LD and TLD models, and to what extent the topics in the TLD model can replace this information.
注釈
子音の数を減らすと、コーパス中のあいまいさを増加する. /bat/ は /boat/ や /bite/ と フレーム /b t/ を共有し, その他, C15 データセットでは /put/, /pad/, /bad/ に b/p, d/p を共有し, C6 データセットでは, /dog/ や /kite/ その他色々 (もういいでしょう) を共有する. 表1に各データセットにおける曖昧なタイプとトークン, すなわち,複数の単語タイプと一致するフレーム内の単語の割合を示す.
| Dataset | C24 | C15 | C6 |
|---|---|---|---|
| Input Types | 1487 | 1426 | 1203 |
| Frames | 1259 | 1078 | 702 |
| Ambig Types % | 27.2 | 42.0 | 80.4 |
| Ambig Tokens % | 41.3 | 56.9 | 77.2 |
6.4 Topics¶
The input to the TLD model includes a distribution over topics for each situation, which we infer in advance from the full Brent corpus (not only the C1 subset) using LDA. Each transcript in the Brent corpus captures about 75 minutes of parent-child interaction, and thus multiple situations will be included in each file. The transcripts do not delimit situations, so we do this somewhat arbitrarily by splitting each transcript after 50 CDS utterances, resulting in 203 situations for the Brent C1 dataset. As well as function words, we also remove the five most frequent content words (be, go, get, want, come). On average, situations are only 59 words long, reflecting the relative lack of content words in CDS utterances.
注釈
TLD モデルへの入力はそれぞれの状況に対する話題の分布を含んでいる. 話題は LDA を使用し, すべてのBrentコーパス( C1 サブセットのみではなく) から前もって推定した. Brent コーパスに含まれるそれぞれの転記は 親子のインタラクション約75分収集しており, そのため, 複数の状態がそれぞれのファイルには含まれている. 転記は状況を限定するものではないため, 我々はやや恣意的に,それぞれの転記を 50 CDS 発話後に分割することによって,Brent C1 データセットに対し, 203 の兄弟を生じさせた. 機能語と同様に5つの頻出する単語を除外した (be, go, get, want, come). CDSの発話中の内容語の相対的な不足を反映して, 状況は平均わずか 59 単語分の長さであった.
Input types are the number of word types with distinct input representations (as opposed to gold orthographic word types, of which there are 1497). Ambiguous types and tokens are those with frames that match multiple (orthographic) word types.
注釈
入力の種類は個別の入力表現を持つ単語の種類の数である ( 1497個ある正式な正投影単語の種類とは対象に) あいまいなタイプとトークンは、複数の(正投影)単語の種類と一致するフレームを持つ.
We infer 50 topics for this set of situations using the mallet toolkit (McCallum, 2002). Hyperparameters are inferred, which leads to a dominant topic that includes mainly light verbs (have, let, see, do). The other topics are less frequent but capture stronger semantic meaning (e.g. yummy, peach, cookie, daddy, bib in one topic, shoe, let, put, hat, pants in another). The word-topic assignments are used to calculate unsmoothed situation-topic distributions \(theta\) used by the TLD model.
注釈
我々は mallet ツールキットを使用して, これらの状況のセットに対するの50のトピックを推測した(McCallum, 2002). 主に軽動詞 ( have, let, see, do ) を含む支配的な話題につながるハイパーパラメータが推定された. その他の話題はあまり起きなかったが, 強い意味論的な意味が収集された(例えば, ある話題では yummy, peach, cookie, daddy, bib, 他の話題では shoe, let, put, hat, pants など) 単語-話題割り当てはTLDモデルによって, 平滑化されていない情報-話題分布 \(theta\) を計算するために使用される.
6.5 Evaluation¶
We evaluate against adult categories, i.e., the ‘goldstandard’, since all learners of a language eventually converge on similar categories. (Since our model is not a model of the learning process, we do not compare the infant learning process to the learning algorithm.) We evaluate both the inferred phonetic categories and words using the clustering evaluation measure V-Measure (VM; Rosenberg and Hirschberg, 2007). [8] VM is the harmonic mean of two components, similar to F-score, where the components (VC and VH) are measures of cross entropy between the gold and model categorization.
注釈
言語のすべての学習者は、最終的には類似したカテゴリに収束するので私たちは、大人のカテゴリ,つまり”ゴールデンスタンダート”に対して評価を行った. (我々のモデルは、学習プロセスのモデルではないので、 我々は、学習アルゴリズムと幼児学習プロセスを比較しない) 我々は推定された音素カテゴリと単語の両方をクラスタリングの評価尺度 V-Measure によって評価した (VM; Rosenberg and Hirschberg, 2007). [8]
For vowels, VM measures how well the inferred phonetic categorizations match the gold categories; for lexemes, it measures whether tokens have been assigned to the same lexemes both by the model and the gold standard. Words are evaluated against gold orthography, so homophones, e.g. hole and whole, are distinct gold words.
注釈
母音に対しては VM を どのくらいよく正解カテゴリとマッチする音素カテゴリを推定できたかによって計測している. 語彙素性に対してはトークンがゴールデンスタンダードとモデルの両方で同じ語彙素性に割り当てられたか否かで計測した. 単語は標準化記述に対して評価され, そのため同音異義語 (hole と whole) は個別の正解単語とした.
脚注
| [8] | (1, 2) Other clustering measures, such as 1-1 matching and pairwise precision and recall (accuracy and completeness) showed the same trends, but VM has been demonstrated to be the most stable measure when comparing solutions with varying numbers of clusters (Christodoulopoulos et al., 2010). 他のクラスタリング尺度,例えば 1-1 マッチング や ペアごとの recall, precision ( accuracy や completeness ) でも同じ傾向を示すが, VM はクラスターの数が異なるソリューションを比較する際に 最も安定性のある尺度であることが示されている(Christodoulopoulos et al., 2010). |
6.6 Results¶
We compare all three models—TLD, LD, and IGMM—on the vowel categorization task, and TLD and LD on the lexical categorization task (since IGMM does not infer a lexicon). The datasets correspond to two sets of conditions: firstly, either using vowel categories synthesized from all speakers or only adult female speakers, and secondly, varying the coarseness of the observed consonant categories. Each condition (model, vowel speakers, consonant set) is run five times, using 1500 iterations of Gibbs sampling with hyperparameter sampling. Overall, we find that TLD outperforms the other models in both tasks, across all conditions.
注釈
我々は 3つのモデル —TLD, LD, IGMM— すべてを母音分類タスク,で比較し, TLD モデル と LDモデル を語彙の分類タスクで比較した( IGMM は語彙を推定しないため). データセットは2組の条件に対応している. まず, すべてのまたは,女性のみの話者のどちらかから合成された母音カテゴリを使用する条件. つづいて, 観察された子音のカテゴリの粗さを変化させる条件である. 各条件 (モデル, 母音話者, 子音のセット) は五回ずつ実行され, ハイパラメータサンプリングをもつ Gibbd サンプリング の反復を 1500 回行った. 総括すると TLD モデルはすべての条件,両方のタスクで他のモデルよりも良い性能であることが分かった.
Vowel categorization results are shown in :num:`Figure #fig3`. IGMM performs substantially worse than both TLD and LD, with scores more than 30 points lower than the best results for these models, clearly showing the value of the protolexicon and repli- cating the results found by Feldman et al. (2013a) on this dataset. Furthermore, TLD consistently outperforms the LD model, finding better phonetic categories, both for vowels generated from the combined categories of all speakers (‘all’) and vowels generated from adult female speakers only (‘w’), although the latter are clearly much easier for both models to learn. Both models perform less well when the consonant frames provide less information, but the TLD model performance degrades less than the LD performance.
注釈
母音のカテゴリ化の結果を :num:`図 #fig3` に示す. IGMMは常に TLD, LD 双方より悪い成績であり, このデータセット上の Feldman et al. (2013a) で発見された結果の反復であり, はっきりと 前-語彙の値を示しているこれらのモデルの最もよい値より 30 ポイント以上スコアが低い. 更に, TLD モデルは常に LD モデルよりも性能がよく, 全てのスピーカーの組み合わせのカテゴリから生成された母音’all’, 成人女性のみの発話だけから生成された母音 ‘W’ 両方で, 後者の方が2つのモデルともに学習が容易であるが, より良い音素カテゴリを発見できた. 子音フレーム提供する情報がが少ない場合, 両モデルの機能は低下する. しかし, この低下はTLDモデルの方が, LD モデルよりも少ない.

母音の評価
- ‘all’ : すべての話者からの合成した母音セットを使用
- ‘w’ : 成人女性の母音から合成した母音セットを使用
バーは五回の実行を基準に95%信頼区間を示す. ここには示していないが, IGMMの結果は以下の通りである.
- IGMM-all : VM score of 53.9 (CI=0.5)
- IGMM-w : VM score of 65.0 (CI=0.2)
The gold-standard vowels are shown in gold in the background but are mostly overlapped by the inferred categories.
注釈
ゴールドスタンダードの母音は、バックグラウンドに金色で示されているが、ほとんどは推論されたカテゴリ毎に重なっている.
Both the TLD and the LD models find ‘supervowel’ categories, which cover multiple vowel categories and are used to merge minimal pairs into a single lexical item. :num:`Figure #fig4` shows example vowel categories inferred by the TLD model, including two supervowels. The TLD supervowels are used much less frequently than the supervowels found by the LD model, containing, on average, only twothirds as many tokens.
注釈
TLD , LD モデル 両方とも 複数の母音カテゴリにまたがり,一つの語彙的アイテムに含まれるミニマルペアを結合している “上位母音” カテゴリを発見している. :num:`図 #fig4` に TDL モデルによって推定された2つの上位母音を含む母音カテゴリの例を示す. TDL モデルでの上位母音は平均してトークンの \(\frac{2}{3}\) 程度の, LDモデルが発見した上位母音より少ない頻度が使用されている.

TLD モデルによって発見された母音:
:num:`Figure #fig5` shows that TLD also outperforms LD on the lexeme/word categorization task. Again performance decreases as the consonant categories become coarser, but the additional semantic information in the TLD model compensates for the lack of consonant information. In the individual components of VM, TLD and LD have similar VC (‘recall’), but TLD has higher VH (‘precision’), demonstrating that the semantic information given by the topics can separate potentially ambiguous words, as hypothesized.
注釈
:num:`図 #fig5` に TLD モデルが 語彙素性/単語のカテゴリ化タスクで LD モデルよりも優れていることを示す. ここでも,子音のカテゴリは、粗くなればなるほど,パフォーマンスの低下が見られるが, TLD モデルにおける意味情報の追加は子音情報の不足を補償している. VMの個々の成分を確認するとTLDとLDは、類似したVC(’recall’)を持っているが, TLDは、より高いVH(’precision’)を有している. この結果は話題によって与えられた意味情報が、潜在的にあいまいな言葉を分離することができるという仮説を実証するものである.
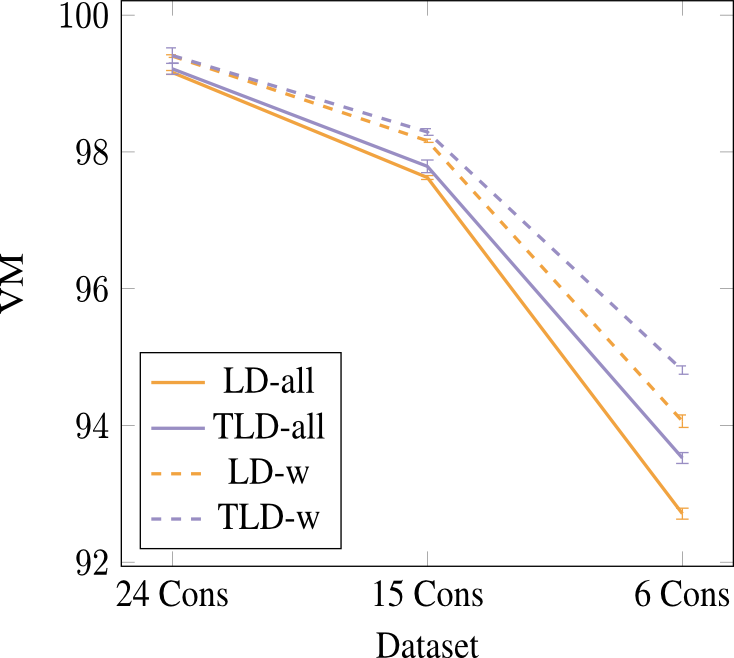
語彙素性の評価
- ‘all’ : すべての話者から合成された母音を含むデータセットを使用
- ‘w’ : 成人女性の母音から合成された母音を含むデータセットを使用
Overall, the contextual semantic information added in the TLD model leads to both better phonetic categorization and to a better protolexicon, especially when the input is noisier, using degraded consonants. Since infants are not likely to have perfect knowledge of phonetic categories at this stage, semantic information is a potentially rich source of information that could be drawn upon to offset noise from other domains. The form of the semantic information added in the TLD model is itself quite weak, so the improvements shown here are in line with what infant learners could achieve.
注釈
結論として, TLD モデルで追加された文脈の意味情報は音素カテゴリ化と 源-語彙 の両方をより良くする. これは子音情報が劣化してノイズが多いときには特に顕著になる. 乳児は、この段階で音素カテゴリの完全な知識を持っていそうにないため, 意味情報は,潜在的に他のドメインからのノイズをうまく相殺することのできる豊かな情報源なのである. TLDモデルで追加された文脈の意味情報はそれ自体は非常に弱いが, ここに示した改善は幼児学習者が達成できるものと一致している.
7 Conclusion¶
Language acquisition is a complex task, in which many heterogeneous sources of information may be useful. In this paper, we investigated whether contextual semantic information could be of help when learning phonetic categories. We found that this contextual information can improve phonetic learning performance considerably, especially in situations where there is a high degree of phonetic ambiguity in the word-forms that learners hear. This suggests that previous models that have ignored semantic information may have underestimated the information that is available to infants. Our model illustrates one way in which language learners might harness the rich information that is present in the world without first needing to acquire a full inventory of word meanings.
注釈
言語獲得は複雑な課題であり, その中では多くの異なった情報源があることが有益である. 本稿では, 文脈の意味的な情報は音素のカテゴリ学習を行う際に有益なのか否かを調査した. われわtrはこの文脈情報は, 特に学習者が耳にする単語フォームの中に重度の音素的な曖昧性がある場合に, 音素学習のパフォーマンスをかなり向上させることができることを発見した. この結果は意味的な情報を無視していた先行モデルは乳児の利用できる情報を過小評価していたかもしれないことを示唆する. 我々のモデルは言語の学習者が,最初に完全な単語の意味インベントリを取得することがなくとも, 世界中に存在している優れた情報を使用できるかもしれない方法の一つを提示した.
The contextual semantic information that the TLD model tracks is similar to that potentially used in other linguistic learning tasks. Theories of cross-situational word learning (Smith and Yu, 2008; Yu and Smith, 2007) assume that sensitivity to situational co-occurrences between words and non-linguistic contexts is a precursor to learning the meanings of individual words. Under this view, contextual semantics is available to infants well before they have acquired large numbers of semantic minimal pairs. However, recent experimental evidence indicates that learners do not always retain detailed information about the referents that are present in a scene when they hear a word (Medina et al., 2011; Trueswell et al., 2013). This evidence poses a direct challenge to theories of cross-situational word learning. Our account does not necessarily require learners to track co-occurrences between words and individual objects, but instead focuses on more abstract information about salient events and topics in the environment; it will be important to investigate to what extent infants encode this information and use it in phonetic learning.
注釈
TLDモデル で追跡した文脈の意味論的な情報は潜在的には他の言語の学習タスクで使用することにも似ている. クロス状況語学習の理論 (Smith and Yu, 2008; Yu and Smith, 2007) は 言語的コンテキストと非言語的コンテキストの共起状況への感受性は個々の単語の意味を学習することを促進すると想定している. この視点に立つと, 意味的最小のペアを大量に取得するより前に文脈的意味論がよく乳児に提供さているとされる. しかし, 最近の実験的証拠は学習者が単語を聞くとき, 指示対象に対して存在しているシーンに対して彼らは常に詳細な情報を持っているわけではないことを示している (Medina et al., 2011; Trueswell et al., 2013). この証拠は、クロス状況語学習の理論への直接的な課題を提起する. 我々の主張は決して, 学習者が単語と個々の対象間に起きる共起を追跡する必要があると言っているのではなく, 代わりに, その環境で顕著なイベントやトピックについてのより抽象的な情報に焦点を当てている. 乳児がどの程度,この情報をエンコードし, 音素学習に使用するのかを調査することが必要になるだろう
Regardless of the specific way in which infants encode semantic information, our method of adding this information by using LDA topics from transcript data was shown to be effective. This method is practical because it can approximate semantic information without relying on extensive manual annotation.
注釈
乳児が意味的情報をコード化する特定の方法がどのようなものであるにしろ, 転記情報から LDA トピックモデルを使用することによって 意味的情報を付加する手法は有効であることが示された. この方法は大規模な手動による注釈に依存せず, 意味情報を近似することができるため実用的な方法である.
The LD model extended the phonetic categorization task by adding word contexts; the TLD model presented here goes even further, adding larger situational contexts. Both forms of top-down information help the low-level task of classifying acoustic signals into phonetic categories, furthering a holistic view of language learning with interaction across multiple levels.
注釈
LD モデルは単語コンテキストを追加することで音素カテゴリ化タスクを拡張し, 本稿で紹介した TLD モデルは大きな状況のコンテキストを追加することでさらに先に進んだ. どちらのトップダウン情報の形式でも, 複数のレベル間での相互に作用し,言語学習の全体像を促進し,音響信号を音素カテゴリに分類する低レベルのタスクを手助けする.
Acknowledgments¶
This work was supported by EPSRC grant EP/H050442/1 and a James S. McDonnell Foundation Scholar Award to the final author.
References¶
- Frans Adriaans and Daniel Swingley.
- Distributional learning of vowel categories is supported by prosody in infant-directed speech.
- In Proceedings of the 34th Annual Conference of the Cognitive Science Society (CogSci), 2012.
- Bergelson and D. Swingley.
- At 6-9 months, human infants know the meanings of many common nouns.
- Proceedings of the National Academy of Sciences, 109(9) : 3253-3258, Feb 2012.
- David M. Blei, Thomas L. Griffiths, Michael I. Jordan, and Joshua B. Tenenbaum.
- Hierarchical topic models and the nested Chinese restaurant process.
- In Advances in Neural Information Processing Systems 16, 2003.
- Michael R. Brent and Jeffrey M. Siskind.
- The role of exposure to isolated words in early vocabulary development.
- Cognition, 81(2):B33–B44, 2001.
- Christos Christodoulopoulos, Sharon Goldwater, and Mark Steedman.
- Two decades of unsupervised POS induction: How far have we come?
- In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), pages 575–584, Cambridge, MA, October 2010.
- Association for Computational Linguistics.
- Bart de Boer and Patricia K. Kuhl.
- Investigating the role of infant-directed speech with a computer model.
- Acoustics Research Letters Online, 4(4): 129, 2003.
- Brian Dillon, Ewan Dunbar, and William Idsardi.
- A single-stage approach to learning phonological categories: Insights from Inuktitut.
- Cognitive Science, 37(2):344–377, Mar 2013.
- Micha Elsner, Sharon Goldwater, Naomi Feldman, and Frank Wood.
- A cognitive model of early lexical acquisition with phonetic variability.
- In Proceedings of the 18th Conference on Empirical Methods in Natural Language Processing (EMNLP), 2013.
- word learning.
- Psychological Science, 20(5): 578–585, 2009.
- Manuela Friedrich and Angela D. Friederici.
- Word learning in 6-month-olds: Fast encoding—weak retention.
- Journal of Cognitive Neuroscience, 23 (11):3228–3240, Nov 2011.
- Lakshmi J. Gogate and Lorraine E. Bahrick.
- Intersensory redundancy and 7-month-old infants’ memory for arbitrary syllable-object relations.
- Infancy, 2(2):219–231, Apr 2001.
- Hillenbrand, L. A. Getty, M. J. Clark, and K. Wheeler.
- Acoustic characteristics of American English vowels.
- Journal of the Acoustical Society of America, 97(5 Pt 1):3099–3111, May 1995.
- Jusczyk and Elizabeth A. Hohne.
- Infants’ memory for spoken words.
- Science, 277(5334): 1984–1986, Sep 1997.
- Patricia K. Kuhl, Karen A. Williams, Francisco Lacerda, Kenneth N. Stevens, and Bjorn Lindblom.
- Linguistic experience alters phonetic perception in infants by 6 months of age.
- Science, 255(5044):606–608, 1992.
- Brian MacWhinney.
- The CHILDES Project: Tools for Analyzing Talk.
- Lawrence Erlbaum Associates, 2000.
- Mandel, P. W. Jusczyk, and D. B. Pisoni.
- Infants’ recognition of the sound patterns of their own names.
- Psychological Science, 6(5):314– 317, Sep 1995.
- Nivedita Mani and Kim Plunkett.
- Twelve-montholds know their cups from their keps and tups.
- Infancy, 15(5):445470, Sep 2010.
- Naomi H. Feldman, Thomas L. Griffiths, Sharon Goldwater, and James L. Morgan.
- A role for the developing lexicon in phonetic category acquisition.
- Psychological Review, 2013a.
- Jessica Maye, Daniel J. Weiss, and Richard N. Aslin.
- Statistical phonetic learning in infants: facilitation and feature generalization.
- Developmental Science, 11(1):122–134, Jan 2008.
- Naomi H. Feldman, Emily B. Myers, Katherine S. White, Thomas L. Griffiths, and James L. Morgan.
- Word-level information influences phonetic learning in adults and infants.
- Cognition, 127(3): 427–438, 2013b.
- Jessica Maye, Janet F Werker, and LouAnn Gerken.
- Infant sensitivity to distributional information can affect phonetic discrimination.
- Cognition, 82(3):B101–B111, Jan 2002.
Abdellah Fourtassi and Emmanuel Dupoux. A rudimentary lexicon and semantics help bootstrap phoneme acquisition. Submitted.
Michael C. Frank, Noah D. Goodman, and Joshua B. Tenenbaum. Using speakers’ referential intentions to model early cross-situational
Andrew McCallum. MALLET: A machine learning for language toolkit, 2002.
Bob McMurray, Richard N. Aslin, and Joseph C. Toscano. Statistical learning of phonetic categories: insights from a computational approach. Developmental Science, 12(3):369–378, May 2009.
Tamara Nicol Medina, Jesse Snedeker, John C.
Trueswell, and Lila R. Gleitman. How words
can and cannot be learned by observation. Proceedings of the National Academy of Sciences,
108(22):9014–9019, 2011.
Radford Neal. Markov chain sampling methods
for Dirichlet process mixture models. Journal
of Computational and Graphical Statistics, 9:
249–265, 2000.
Linda Polka and Janet F. Werker. Developmental changes in perception of nonnative vowel
contrasts. Journal of Experimental Psychology: Human Perception and Performance, 20(2):421– 435, 1994. ceedings of the 44th Annual Meeting of the Association for Computational Linguistics (ACL), pages 985 – 992, Sydney, 2006.
Tuomas Teinonen, Richard N. Aslin, Paavo Alku, and Gergely Csibra. Visual speech contributes to phonetic learning in 6-month-old infants. Cognition, 108:850–855, 2008.
Erik D. Thiessen. The effect of distributional information on children’s use of phonemic contrasts. Journal of Memory and Language, 56(1):16–34, Jan 2007.
- Tincoff and P. W. Jusczyk. Some beginnings of word comprehension in 6-month-olds. Psychological Science, 10(2):172–175, Mar 1999.
Carl Rasmussen. The infinite Gaussian mixture model. In Advances in Neural Information Processing Systems 13, 2000.
Ruth Tincoff and Peter W. Jusczyk. Six-montholds comprehend words that refer to parts of the body. Infancy, 17(4):432444, Jul 2012.
Andrew Rosenberg and Julia Hirschberg. Vmeasure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 12th Conference on Empirical Methods in Natural Language Processing (EMNLP), 2007.
- Trubetzkoy. Grundz¨ ge der Phonologie. Vanu denhoeck und Ruprecht, G¨ ttingen, 1939. o
Brandon C. Roy, Michael C. Frank, and Deb Roy. Relating activity contexts to early word learning in dense longitudinal data. In Proceedings of the 34th Annual Conference of the Cognitive Science Society (CogSci), 2012.
Rushen Shi and Janet F. Werker. The basis of preference for lexical words in 6-month-old infants. Developmental Science, 6(5):484–488, 2003.
- Shukla, K. S. White, and R. N. Aslin. Prosody guides the rapid mapping of auditory word forms onto visual objects in 6-mo-old infants. Proceedings of the National Academy of Sciences, 108 (15):6038–6043, Apr 2011.
Linda B. Smith and Chen Yu. Infants rapidly learn word-referent mappings via cross-situational statistics. Cognition, 106(3):1558–1568, 2008.
Christine L. Stager and Janet F. Werker. Infants listen for more phonetic detail in speech perception than in word-learning tasks. Nature, 388: 381–382, 1997.
- Swingley. Contributions of infant word learning to language development. Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1536):3617–3632, Nov 2009.
Yee Whye Teh. A hierarchical Bayesian language model based on Pitman-Yor processes. In Pro-
John C. Trueswell, Tamara Nicol Medina, Alon Hafri, and Lila R. Gleitman. Propose but verify: Fast mapping meets cross-situational word learning. Cognitive Psychology, 66:126–156, 2013.
- Vallabha, J. L. McClelland, F. Pons, J. F. Werker, and S. Amano. Unsupervised learning of vowel categories from infant-directed speech. Proceedings of the National Academy of Sciences, 104(33):13273–13278, Aug 2007.
Janet F. Werker and Richard C. Tees. Crosslanguage speech perception: Evidence for perceptual reorganization during the first year of life. Infant Behavior and Development, 7:49–63, 1984.
- Henny Yeung and Janet F. Werker. Learning words’ sounds before learning how words sound: 9-month-olds use distinct objects as cues to categorize speech information. Cognition, 113(2): 234–243, Nov 2009.
- Chen Yu and Linda B. Smith.
- Rapid word learning under uncertainty via cross-situational statistics.
- Psychological Science, 18(5):414–420, 2007.
警告
Citation for published version:
Frank, S, Feldman, N & Goldwater, S 2014, ‘Weak semantic context helps phonetic learning in a model of infant language acquisition’. in Proceedings of the 52nd Annual Meeting of the Association of Computational Linguistics. Association for Computational Linguistics.
注釈
Link
Link to publication record in Edinburgh Research Explorer
注釈
Published In
Proceedings of the 52nd Annual Meeting of the Association of Computational Linguistics
警告
General rights
Copyright for the publications made accessible via the Edinburgh Research Explorer is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights.
警告
Take down policy
The University of Edinburgh has made every reasonable effort to ensure that Edinburgh Research Explorer content complies with UK legislation. If you believe that the public display of this file breaches copyright please contact openaccess@ed.ac.uk providing details, and we will remove access to the work immediately and investigate your claim.