モデルについて¶
ディレクレ過程事前分布¶
- 音素カテゴリのセットと語彙は ノンパラメトリックなディリクレ過程 (DP) 事前分布でモデリングされている.
これは, 潜在的には無限個のカテゴリや語彙を返す.
- 一つの DP は パラメタ \(DP(\alpha, H)\) によって規定される.
- \(\alpha\) : 実数値(クラスタ数の決定に寄与)
- \(H\) : ベースとなる分布
- \(H\) はそれが音素カテゴリのリストとして語彙を生成する場合や, フォルマント空間の音素カテゴリを生成する場合などには, 連続値をとる.
- 資料: http://www.smapip.is.tohoku.ac.jp/~dex-smi/2008/pip-miru2008/KenichiKurihara.pdf
\(DP, G ~ (\alpha, H)\) からの描画は \(H\) からの描画のセット上に, \(H\) によって例えば, 生成されたカテゴリまたは語彙素のセットに対する離散分布などの分布を返す.
- 混合モデル設定
- \(H\) 由来の対応するコンポーネントによって生成されたデータポイントを持つ, カテゴリの割り当てを \(G\) から生成する
- \(H\) が無限の場合, \(DP\) のサポートもまた無限である.
- 推論の間, \(G\) を最小化した.
IGMM (ベースモデル)¶
- 母音学習の先行研究 (de Boer and Kuhl, 2003; Vallabha et al., 2007; McMurray et al., 2009; Dillon et al., 2013) にしたがって, 我々は, 母音トークンは ガウス混合分布モデルにしたがって起きるものであると過程した.
- Infinite Gaussian Mixture Model (IGMM) は上述の DP を含む - 基本分布 \(H_C\) : Normal Inverse-Wishart事前分布から描かれる多変量カウス分布
- 各観測では, フォルマントベクトル \(w_{ij}\) はカテゴリ割り当て \(c_{ij}\) に対応するガウシアンより描かれる.
- 上記のモデルはそれぞれの母音トークン \(w_{ij}\) に対するカテゴリ割り当て \(c_{ij}\) を生成する.
- これが, ボトムアップな分布の情報のみを使用して母音トークンをクラスタ化する IGMM モデルである.
Lexicon¶
LD モデルはトークンレベルで語彙内のカテゴリを割り当てるのではなく、トップダウンの情報が追加される.
単語トークン = \(x_i\)
- 単語トークンのフレーム = \(f_i\)
- これは子音のリストと母音のスロットと, 母音トークン \(w_i\) のリストで構成されている ( TLD モデルでは, 以下に記載する追加の対象も含む ).
母音トークン = \(w_{ij}\) = 第一,第二フォルマントのベクトル
母音カテゴリ = \(w_{ij} =c\)
- 中間の語彙 = \(f_{\ell}\)
- これは フレーム \(f_{\ell}\) と 母音カテゴリの割り当て \(\nu_{\ell j} = c\) を含む.
- 単語トークンがある語彙に割り当てられた場合 = \(x_i = \ell\)
- その語に含まれる母音は語彙の母音カテゴリに割り当てられる = \(w_{ij} = \nu_{\ell j} =c\)
その単語フレームと語彙フレームは一致する = \(f_i = f_{\ell}\) .
注釈
\(f_i\) の具体例
\(x_i\) = “Kitty”
- \(f_i = \text{k\_t\_}\) を持ち, 2つの母音スロットをその間に持つ, 2つの子音音素/k/, /t/を持ち, そして2つの母音ベクトル \(w_{i0} = [464, 2294] \text{ and } w_{i1} = [412, 2760]\) を持つ.
注釈
語彙を導入する利点と欠点
語彙情報はカテゴリの重度な重複の曖昧さをなくすため,音素のカテゴリゼーションを手助けする. \(ae-eh\) 領域のデータポイントの中心を観察する純粋な分布学習者はカテゴリの分布が非常に似ているため, これらすべてのポイントは単一のカテゴリであると割り当てるだろう. しかし, 語彙コンテキストに注目する学習者は \(ae\) は \(ae-eh\) 領域の一部で 観察されるというコンテキストと, 一方 \(eh\) は異なる(ただし部分的には重複する) 空間でのみ観察されると いうコンテキストがあるため, 違いに気がつくことができる. そのため, 学習者は2つの異なるカテゴリが異なる語彙のセットにおいて生じるという証拠を持っている.
LDモデルのシミュレーションは音素学習を制約する語彙情報を用いることで大幅に分類精度を向上させることができることを示しており(Feldman et al., 2013a), それはまた、エラーを導くことにもなりうる. 異なる母音で同じ子音のフレームを含む二語のトークン(すなわち、ミニマルペア)では, モデルは、これら二つの母音を同じものとして分類する可能性が高い. したがって, このモデルではミニマルペアの区別は難しい. 一方, 乳児もまたミニマルペアに関しては問題があり (Stager and Werker, 1997; Thiessen, 2007), LD モデルは問題の程度を過大評価できる. 我々は学習者が(子供がそうであるように)その使用の文脈で言葉を関連付けすることができる場合には, その正確な意味を知らなくても ミニマルペアの曖昧性に対する弱い情報源を提供することができると仮定した. これは,学習者が異なる状況のコンテキストで \(k V_1 t\) と \(k V_2 t\) という語を聞いた場合, それらの間の語彙的類似性にもかかわらず, それらは異なる語彙項目である可能性が高く (そして \(V_1\) と \(V_2\) は異なる音素である) と判断できる.
LDモデルでは、母音音素は、語彙から引き出された単語中に現れる.
それぞれの語彙素性はフレームと母音カテゴリ \(\nu_{\ell}\) のリストとして表現される.
語彙素性は語彙生成基本分布 \(H_L\) を持つ DP から描かれる.
単語に含まれるそれぞれの母音トークンのカテゴリは語彙素性ごとに探索される.
IGMMのように, フォルマントの値は対応するガウシアンから描かれる.
\(H_L\) は幾何分布から最初に描かれる音素の数と二峰性の分布由来の子音音素の数とによって, 語彙素性を生成する.
- 上記の IGMM DP \(\nu_{\ell j} ∼ GC\) から 母音音素 \(\nu_{\ell}\) が生成される一方,
- 子音はその後, 均一的な基本分布を持つ DP から生成される
- \(H_L\) からの2つの描写は独立した語彙素性における結果であることに注目.
- これらは, それにもかかわらず、別々の(同音)語彙素であると考えられる.
Topic-Lexical-Distributional Model¶
状況の情報を利用する利点を実証するために, 我々は 話題-単語-分布モデルを開発した.
これはその語が 類似した話題の文章で生じるという Topic モデルを仮定することにより LD モデルを拡張したものである.
それぞれの状況 = \(h\)
観察された話題 = \(\theta_h\)
- ある状況 \(h\) における \(i\) 番目のトークン = \(x_{hi}\)
- そのフレーム \(f_{hi}\), 母音 \(w_{hi}\), そして Topic ベクトル \(\theta_h\) となる.
- TLD モデル は IGMM の母音コンポーネントを保ってはいるが, 話題に限定的な語彙によって LD モデルの語彙を拡張した.
- 語彙素性の確率は話題に由来しているという考えをとったものである.
- 特に, TLD モデルはディレクレ過程の語彙を,階層的ディレクレ過程に置き換えたものである(HDP; Teh (2006)).
HDP 語彙では, LD モデルの場合のように、トップレベルでグローバルな語彙を生成する.
- その後、話題特異な語彙をグローバルな語彙から取り出だす (しかし、グローバルな語彙のサイズが限られていないので、これは、話題に限定的な語彙になる)
- これらの話題に限定的な語彙は LD モデルと似た方法でトークンを生成するために使用される
- 低レベルの話題の語彙は固定値がある.
- これらは話題分布を推論するために使用される LDA モデルの中でトピックの数に一致する(6.4章参照)。
- グローバルな語彙はトップレベル \(DP: G_L ∼ DP (\alpha_{\ell} , H_L )\) として作成される
\(G_L\) は話題レベルの DPs \(G_k ∼ DP (\alpha_k , G_L )\) において基本分布として使用される.
- HDPs を記述するためにフランチャイズの中華料理屋の比喩がよく使われる.
- \(G_L\) は皿(語彙素性)のグローバルな一覧である.
- 話題に限定された語彙はレストランであり,それぞれの皿に対する分布を持っている.
- この分布は座席に座る客(単語トークン)によってテーブルで定義され, これらはそれぞれメニューから一つの皿を給仕する.
- 同じテーブル \(t\) のすべてのトークン \(x\) は同じ語彙素性 \(t\) に割り当てられる.
- 推論(5章)は語彙素性ではなくテーブルの点から定義される.
- 多数のテーブルが同じ皿を \(G_L\) から引く場合、これらのテーブルのトークンは同じ語彙素性を共有します.
- TLD モデルでは,トークンは状況のなかに出現し,これらの状況は話題に対する分布 \(\theta_h\) を持っている.
- それぞれのトークン \(x_{hi}\) は \(\theta_h\) から描かれる, 共通するインデックスが付与されたトピックの割り当て変数 \(z_{hi}\) を持っている.
- \(w_{hij}\) に対するフォルマントの値は LD モデルの場合と同様の方法で描かれ, \(x_{hi}\) に割り当てられた語彙素性を与えられる.
- モデルに従った結果を :num:`図 #fig2` に示す.
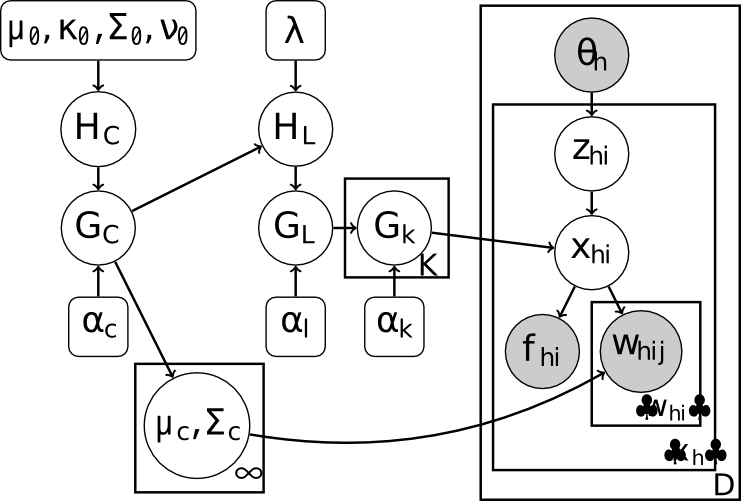
左から右へ TDL モデル, IGMMコンポーネント, LD 語彙コンポーネント, 話題に限定的な語彙, 最後に文章 \(h\) に現れるトークン \(x_{hi}\) と 観察された母音フォルマント \(w_{hij}\) と フレーム \(f_{hi}\)